Methods
System Overview
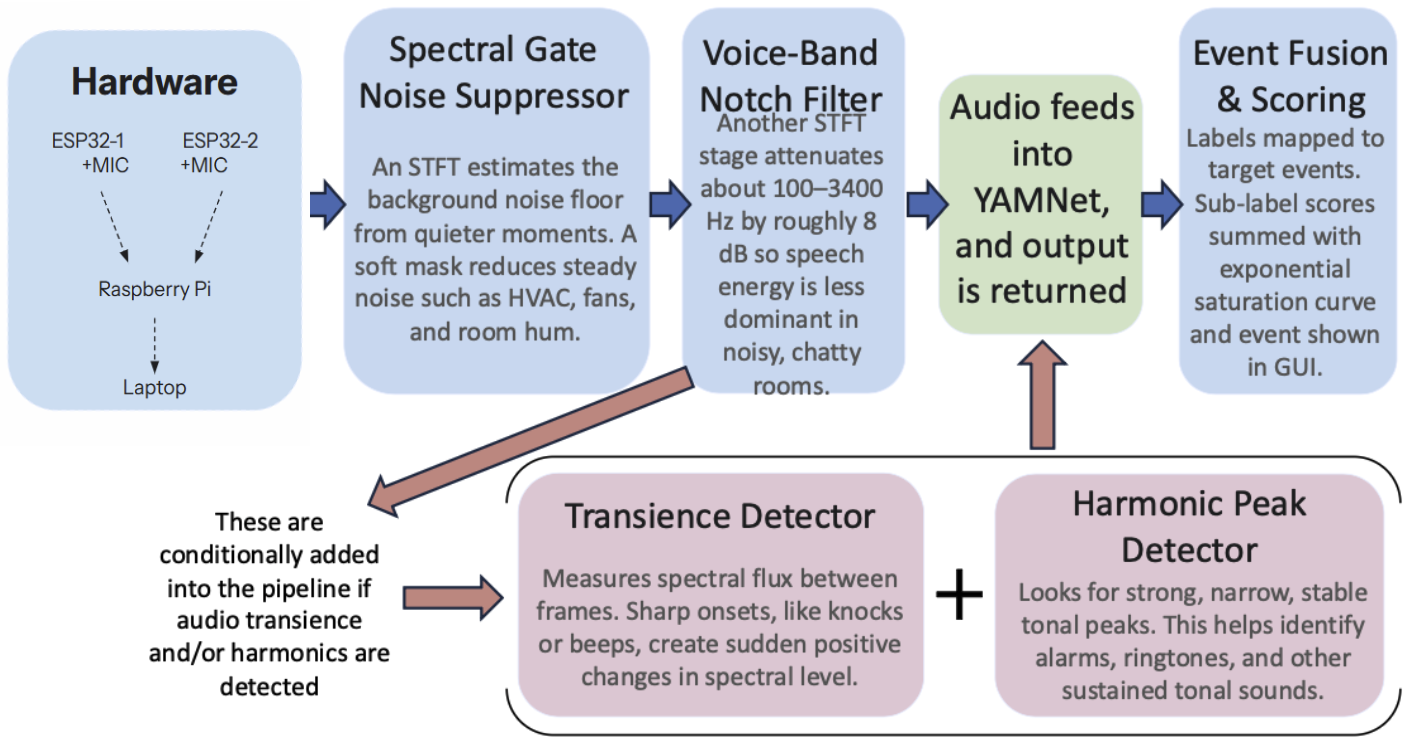
The complete system consists of two ESP32 microphone circuits with analog filtration and wireless data transfer to a laptop, and software implementing the processing and classification pipeline shown in Figure 1.
Pre-Processing Front End
Spectral Gate Noise Suppressor: This part of the system listens for steady, background sounds in the room, such as air conditioning, fans, and low hums, and turns them down. To do this, it uses a Short-Time Fourier Transform (STFT), where it divides the incoming audio into short slices and measures what frequencies are present in each slice. To determine what counts as noise, the program takes the quietest recent slices and classifies them as the room's baseline noise. It then creates a mask which lowers the magnitude of those frequencies rather than completely removing them. This prevents any potentially important audio from being removed entirely. Because the spectral profile of noise will differ between environments, the program continually updates its measuring and classification of baseline noise.
Voice-Band Notch Filter: This second stage turns down the range of pitches human voices occupy, which is roughly 100 to 3,400 Hz. The magnitude of reduction is capped at 8 dB deliberately so events such as doorbells and water running (which occasionally exist in this range as well) aren't fully cut-off. The frequency is capped at 3.4 kHz because alarms and ringtones contain a lot of high-pitched overtones above that threshold.
Classifier and Auxiliary Detectors
The cleaned 5-second audio window is fed into YAMNet, which returns a matrix of confidence scores mapped to different labels. Because YAMNet under weighs very short transient sounds (knocks and single beeps) and very long sustained tonal sounds (some alarms and ringtones), two detectors run in parallel and are conditionally added into the pipeline:
- Transience detector: Computes spectral flux (the difference between consecutive frames). Sharp onsets are created by knocks and beeps, which can then be detected. If they are detected, a multiplier of 1.5 (50% boost) is applied on the labels under the “knock” and “beep” categories (e.g. “door”, “bump”, “beep boop”, “ping”) to increase their confidence scores.
- Harmonic peak detector. Searches for the opposite of a transience detector: narrow, steady tones, which are usually characteristic of fire-alarms and ringtones. If detected, similarly a multiplier of 1.5 is applied to the labels under the “alarm” and “ringtone” categories (e.g. “ring”, “music”, “boom”).
Event Fusion and Scoring
Since YAMNet spreads its confidence across many output labels rather than committing to a single event, the five target events (fire alarm, phone ringtone, microwave beep, doorbell, and water running) are each defined by a list of related YAMNet sub-labels (e.g. “water”, “faucet”, “drip”, and “shower” all under the event “water running”). For the event with the best confidence interval in one sample, the matching sub-label scores are summed and put through an exponential-saturation function:
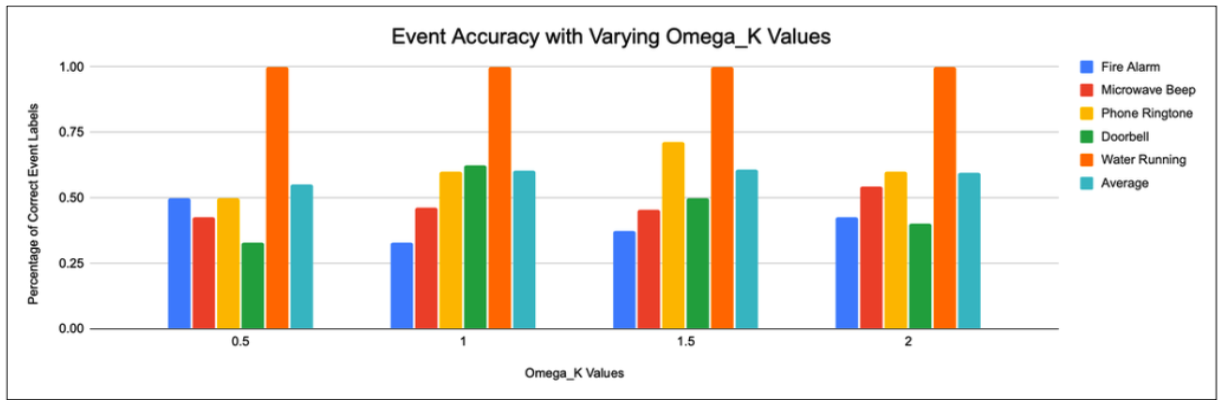
where Ω_K is the coefficient that controls how strongly the sum of confidence values support the claim of the top sound. The exponential form guarantees the final confidence value stays between 0 and 1 regardless of how high the confidence level gets. This equation is crucial for classification as it allows us to combine evidence without over exaggerating the overall confidence level.
An event is finally reported only after a multi-frame voting check is passed. VOTES_REQUIRED is the number of times a specific sound needs to appear as number 1 in the last 10 samples before being declared as the confirmed sound being heard. Every reported event has a minimum cooldown before it can be triggered again. The full set of tunable parameters and their final values is summarized in Table 1.
| Parameter | Final value | Role |
|---|---|---|
| MIN_SCORE | 0.20 | Minimum per-event confidence that counts as a vote. |
| VOTE_WINDOW | 10 | Rolling buffer of the last N inferences used for voting. |
| VOTES_REQUIRED | 2 | Minimum agreeing votes within the window before an event fires. |
| COOLDOWN_S | 6.0 s | Minimum gap between two triggers of the same event. |
| INFER_WINDOW_S | 5.0 s | Length of audio window passed to YAMNet on each inference call. |
| INFER_EVERY_S | 0.5 s | How often inference runs (heavy window overlap). |
| Ω_K | 1.0 | Coefficient in the exponential-saturation event fusion; controls how influential the sum of sub-label confidences is. |
Hardware Implementation
Two integrated ESP32 microphone circuits were built. Each board has an op-amp-based gain before sending signals to the ESP32, which transmits the signals to the Raspberry Pi over Wi-Fi. The Pi drives a GUI that displays the most recently detected event.
Development Cycle
The work was divided into hardware and software. When developing software, YAMNet was analyzed to understand which of the initial parameters had to be changed in order to improve accuracy and decrease false positives. This includes personalization of VOTES_REQUIRED for specific sounds. For short burst sounds like a doorbell (and possibly phone ring) with long pauses in between, it would make sense for that number to be lower than the rest. Additionally, the spectral-flux transience detector and the harmonic peak detector was developed and implemented into the algorithm to help with these kinds of specific distinctions between sounds. Before the integration of software and hardware, all testing of the algorithm was done on a laptop to ensure time efficiency while the device was being developed. Testing was done in three different environments: a library, a dorm kitchen, and a building hallway. These were used to profile realistic noise floors.
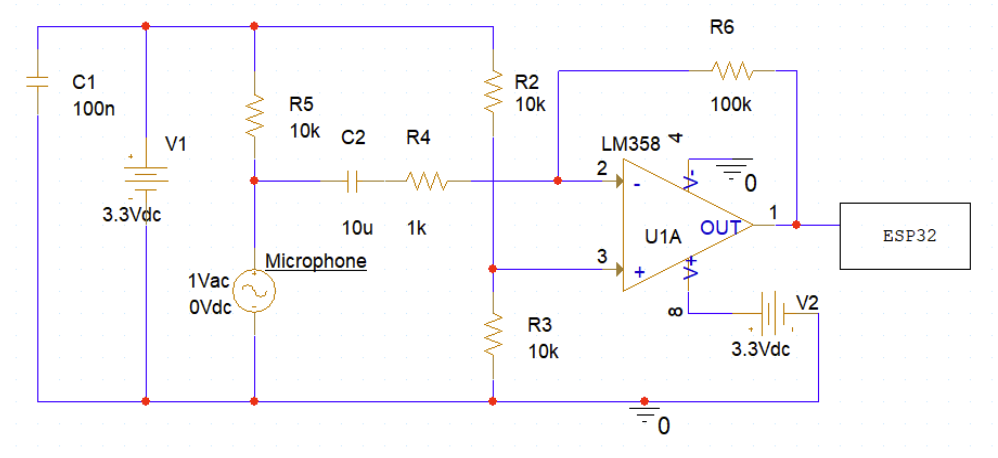
The hardware development started with the lab microphone amplifier circuit from ESE 3310. First, we modified the microphone lab circuit from ESE 3310 so that the input from the microphone passes through an analog-to-digital converter to be processed on a Raspberry Pi.
There were several changes made to the circuit from the original lab circuit. Normally, sound inputs in the time domain are centered at 0 amplitude, but this will not work for our circuit. Because the Raspberry Pi will run on 3.3V, any voltage outside 0-3.3V will not be interpreted. Therefore, a voltage bias at 1.65V must be set, meaning the sound inputs are centered at 1.65V, and the circuit must limit voltage to hit maximums of 3.3V and 0V. The bias will be applied by changing R4 to 10K and voltage is lowered by implementing a voltage divider before feeding data to the MCP3008. The VCC was decreased to input 9V for future implementation of a 9V battery in PCB designs. In order to test this new circuit, we used an oscilloscope and Matlab to observe the output of the opamp through the MCP3008 circuit.
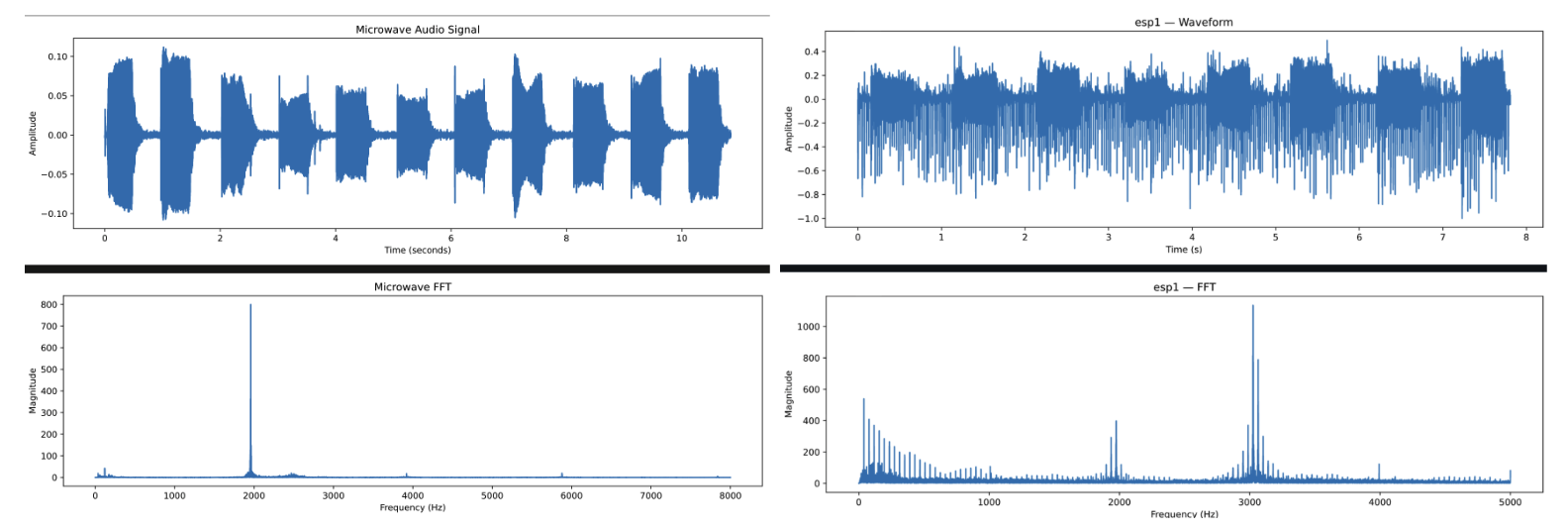
From auditory observation, it was clear that the USB mic had higher quality audio than the MCP3008 mic. Furthermore, the FFT of the output showed that the data using the ADC converter was limited to 2.4Khz. The audio recording limitations of the ADC converter circuit prevented any analysis of fire alarms and microwave sounds, which show peaks at 2Khz and 3Khz respectively. This is alarming because our circuit should have priority in detecting these signals. Because of this we explored other options for the microphone circuits.
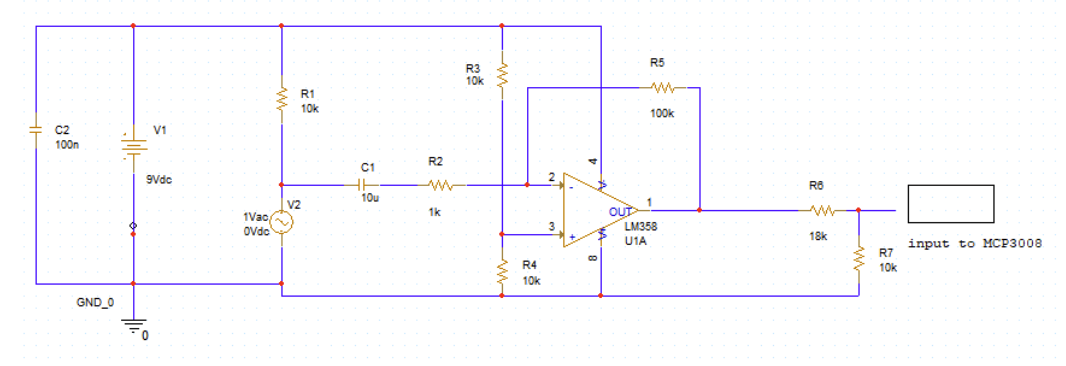
Our second approach was the ESP32 microphone circuit. The ESP32 is advantageous because it has WiFi capabilities, which can be used in transferring audio data to the Raspberry Pi, and a built-in ADC. As shown in Figure 2, the microphone circuit is now attached to the ESP32 and not the Raspberry Pi. With this circuit design, we have the flexibility to collect audio data from multiple ESP32 units, which will transfer data to the Raspberry Pi. There were several changes to the circuit; first, because the ESP32 unit is powered by 3.3V, we powered all parts of the circuit with 3.3V. We removed the voltage divider and changed 9V to 3.3V.
We collected audio data from the ESP32 by compiling an algorithm through Arduino IDE that starts the ESP32 data collection on a specified WiFi port. We graph a sample of the data with a python file activated on the terminal. Data collection showed that the audio data sampled frequencies sufficient for the microwave and fire alarm signals. We used the ESP32 circuit moving forward in the project, and further along created another ESP32 unit and connection to a AA battery holder for portable use.
Initial Errors and Mitigations
- Hardware mismatch. The ESP32 circuits initially displayed incorrectly in the program because of inconsistent normalization and unstable Wi-Fi connections through the institution network. Both were eventually rectified. The ESP's can only handle audio processing at 10 kHz which requires the algorithm to resample the processed audio to be able to insert into YAMNet. Before integration of software and hardware, the algorithm was developed based on the microphone from a personal computer which comes with a high-end microphone compared to the one from the device. Consequently, initial testing resulted in making multiple changes to the algorithm to account for the microphone and ESP shortcomings. This includes, resampling and averaging to cleanup the audio signal being received.
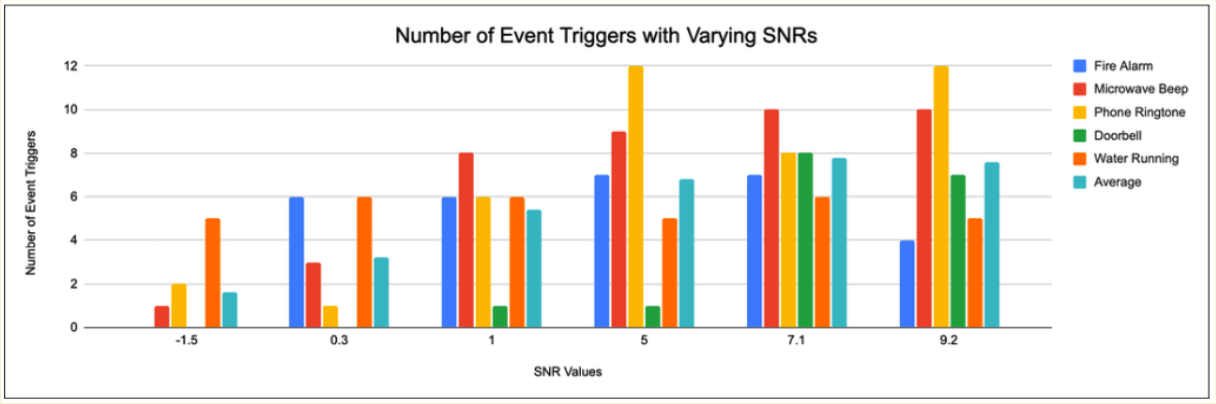
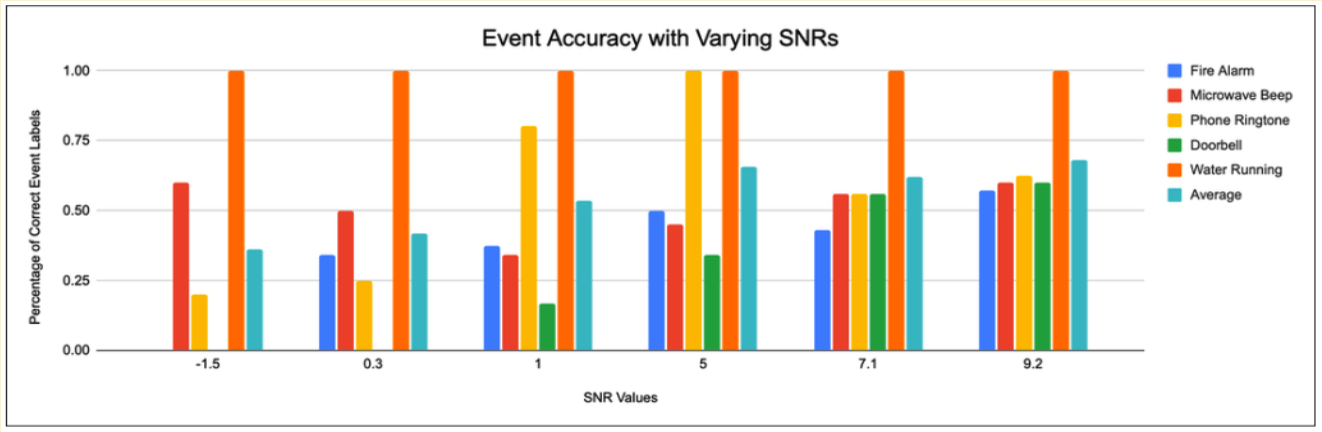
- Noise-floor drift: A fixed noise estimate failed when the device was moved between environments (especially from library to the kitchen). The fix was a rolling percentile-based estimate.
- Latency vs. accuracy. A 10-second analysis window gave the best accuracy but felt too unresponsive. A 5-second window with overlapping 0.5-second loops was chosen as the final compromise.